Jeśli potrzebujemy zdefiniować jakąś relację (dajmy na to małżeństwo) jako symetryczną, to posługując się językiem logiki matematycznej możemy ją zapisać mniej więcej tak:

Przekładając to na zapis charakterystyczny dla Prologu i dokładając jeszcze kilka faktów dotyczących znanych nam małżeństw uzyskamy:
|
1 2 3 4 5 |
married(X, Y) :- married(Y, X). married(adam, ewa). married(andrzej, aleksandra). married(tadeusz, zofia). |
Jest to kod syntaktycznie poprawny, więc kompilator w żaden sposób nie powinien zaprotestować. Czy jednak tak stworzona reguła jest aby na pewno poprawna? Zobaczmy co stanie się, kiedy na naszej bazie faktów wykonamy zapytanie, którym będziemy chcieli uzyskać informację na temat żony Tadeusza:
|
1 2 3 |
| ?- married(Wife, tadeusz). Fatal Error: local stack overflow (size: 8192 Kb, environment variable used: LOCALSZ) |
Skoro w tak prostym programie (możemy go nawet ograniczyć do reguły oraz jednego tylko faktu) wystąpiło przepełnienie bufora, to najwyraźniej swoim zapytaniem spowodowaliśmy wejście w nieskończoną pętlę. Słusznie domyślamy się, że zachowanie to jest skutkiem wykonania pierwszej linii naszej bazy danych. Może więc powinniśmy ulokować fakty przed regułą?
|
1 2 3 4 5 |
married(adam, ewa). married(andrzej, aleksandra). married(tadeusz, zofia). married(X, Y) :- married(Y, X). |
Niestety to również nie rozwiązuje naszego problemu. Wprawdzie dzięki zastosowanemu zabiegowi Prolog jest teraz w stanie odpowiedzieć na interesujące nas pytanie, jednak jeśli udzielona odpowiedź nie zadowoli nas i postanowimy wybrać opcję wygenerowania wszystkich rozwiązań, to znów spowodujemy nieskończoną pętlę. Dlaczego tak się dzieje? Wynika to z algorytmów unifikacji i rezolucji, które wykorzystywane są przy wykonywaniu zapytań. Kolejność wywołań dla zapytania married(Wife, tadeusz) zdeterminowana jest przez następujący schemat działania:
- Algorytm przeszukuje bazę od początku, próbując znaleźć fakt odpowiadający zapytaniu married(Wife, tadeusz) – Wife jest tu oczywiście zmienną.
- Dociera do linii numer 5, gdzie za Y zostaje podstawiony term tadeusz.
- Konieczna jest unifikacja wyrażenia married(tadeusz, X). Prolog zapamiętuje bieżące miejsce i znów rozpoczyna przeglądanie bazy od początku, tym razem szukając odpowiedzi na nowe zapytanie.
- W linii numer 3 znajduje pasujący fakt married(tadeusz, zofia)., który sprawia, że klauzula z linii 5 może być uznana za prawdziwą. Program zwraca więc odpowiedź Wife = zofia, ale nie wypisuje wiadomości yes ponieważ istnieje alternatywna ścieżka unifikacji wyrażenia married(tadeusz, X).
- Prolog powraca więc do sprawdzenia kolejnego rozwiązania – jest nim podstawienie X=tadeusz w linii 5. Otrzymujemy w ten sposób nowe wyrażenie: married(Y, tadeusz).
- Tą drogą znów docieramy do punktu pierwszego i powtarzamy wszystkie kroki w nieskończoność.
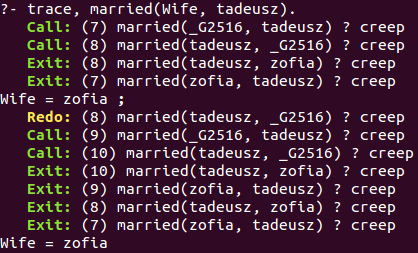
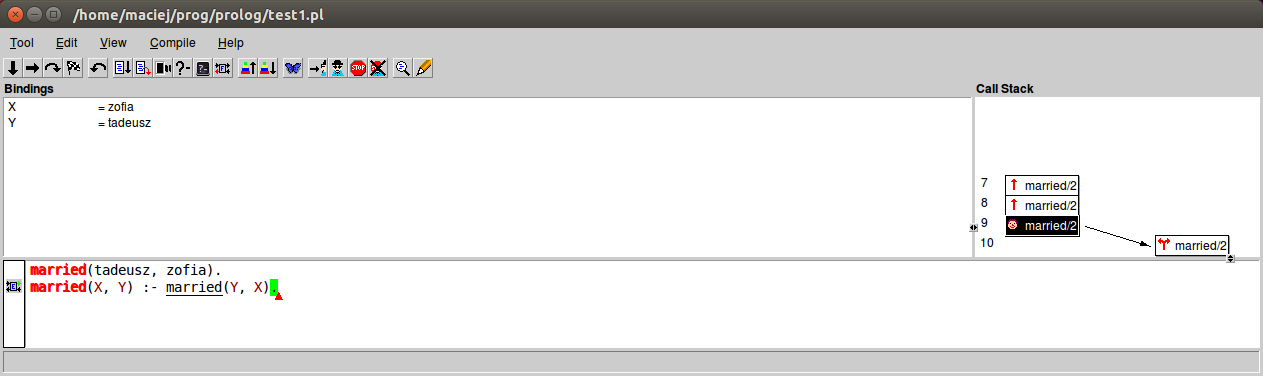
Pomocnymi przy analizie tego typu problemów są narzędzia do debugowania dostarczane razem z implementacją SWI-Prolog: trace oraz gtrace. Pierwsze z nich prezentuje wyniki w postaci tekstowej, natomiast gtrace uruchamia GUI i generuje grafikę przedstawiającą drzewo wywołań oraz pokazuje które linie programu są wykonywane w kolejnych krokach.
Rozwiązania
Najpopularniejszym i najbardziej zalecanym sposobem rozwiązania problemu związanego z definiowaniem relacji symetrycznej jest wprowadzenie dodatkowej pomocniczej relacji. Dzięki temu wykonanie zapytania takiego jak married(Wife, tadeusz) nie spowoduje już próby wyświetlenia nieskończonej liczby identycznych rozwiązań. Zastosowanie tego rozwiązania obrazuje poniższy przykład:
|
1 2 3 4 |
married(X, Y) :- marriage(X, Y). married(X, Y) :- marriage(Y, X). marriage(tadeusz, zofia). |
Drugim rozwiązaniem – rzadszym i raczej odradzanym ze względu na mniejszą czytelność oraz pewne skutki uboczne – jest zastosowanie operatora @<, który sprawdza czy jedna ze zmiennych występuje przed drugą w tzw. Standard Order of Terms. Poniższy kod również przerywa więc nieskończoną pętlę:
|
1 2 3 4 5 |
married(adam, ewa). married(andrzej, aleksandra). married(tadeusz, zofia). married(X, Y) :- X @< Y, married(Y, X). |
A jaki jest generyczny sposób, który pozwala unikać tego typu problemów? Jest nim zapoznanie się z mechanizmem, który jest w Prologu używany do znajdowania rozwiązań. Wiedząc jak wygląda ścieżka wywołań, gdzie i dlaczego program wykonuje nawroty, jak zachodzi unifikacja itd. zredukujemy szansę, że zaskoczą nas przepełnienia buforów i inne dziwne rezultaty działania prologowych aplikacji.
Źródła
- Prolog — symetrical predicates (Stack Overflow).
- P. Fulmański, Programowanie w logice Prolog, 2009.

1 thought on “Relacje symetryczne w Prologu”