Całkiem niedawno miałem okazję zmierzyć się z dość ciekawym wyzwaniem technicznym (aka zadaniem rekrutacyjnym). Chociaż to, co było do zrobienia, opisać można w kilku słowach, to implementacja nie jest już wcale taka trywialna i dostarczyła mi sporo zabawy oraz możliwości nauczenia się paru nowych rzeczy. Z tego też powodu uznałem, że jest to zadanie, z gatunku tych, którymi warto się podzielić. Na moim GitHubie znajdziecie jego rozwiązanie, zaś poniżej skróconą treść:
Należy zaimplementować serwer zasobów, posiadający dwa zabezpieczone endpointy:
/current_time– zwracający bieżący tekst w postaci sformatowanego tekstu/epoch_time– zwracający czas uniksowyNależy równeż stworzyć serwer autoryzacyjny OAuth 2.0 oraz klienta, który będzie otrzymywał token (w formacie JWT), a następnie przy jego pomocy uzyskiwał żądane zasoby. Zakładamy, że klient (id= „1234”, secret = „qwerty”) jest już zarejestrowany w serwerze autoryzacyjnym oraz, że flow powinien odbywać się zgodnie z procedurą Authorization Code.
Architekturę OAuth 2.0 konieczną do zaimplementowania dobrze ilustruje poniższa grafika:
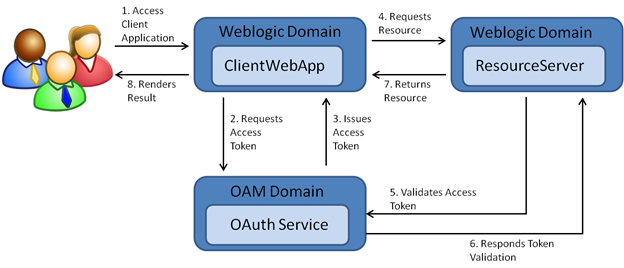
Spis treści
Wstępna analiza
Chociaż z OAuth oczywiście już miałem okazję się zetknąć (podobnie zresztą jak chyba każdy współczesny internauta), to akurat od strony implementacyjnej nigdy wcześniej nie zajmowałem się tym zagadnieniem. Rozwiązywanie zadania rozpocząłem więc od poświęcenia nieco czasu na zapoznanie się z protokołem i koncepcjami, które za nim stoją. Ze swojego doświadczenia mogę zatem polecić poniższe źródła wiedzy:
- oauth.com – Authorization Code Grant
- oauth.net – dokumentacja
- OAuth 2.0 – jak działa / jak testować / problemy bezpieczeństwa
Odpaliłem sobie też w tle trochę youtubowego contentu, np.:
Jeśli nie do końca jeszcze rozumiecie zasadę działania OAuth, to z pewnością przypadnie Wam do gustu wyjątkowo prosta analogia do życia codziennego, która została opowiedziana w powyższym wystąpieniu:
- Recepcja hotelowa – jest odpowiednikiem serwera autoryzacyjnego. Wydaje karty dostępu (tokeny) gościom, którzy dokonali już swojego uwierzytelnienia.
- Karty dostępu – umożliwiają otwarcie tylko konkretnych drzwi w hotelu, dokładnie tak jak access token posiadający określony scope (zakres). Każdy kto posiada kartę, niezależnie od swojej tożsamości, może otworzyć pokój.
- Pokój w hotelu – pełni rolę serwera zasobów. Posiada drzwi z elektronicznym zamkiem, które odczytują kartę i odpytują recepcję o potwierdzenie uprawnień (walidacja tokena).
Po zapoznaniu się z dostępnymi w OAuth 2.0 sposobami autoryzacji można dojść do wniosku, że opisaną w zadaniu architekturę prościej byłoby zaimplementować używając innego flow, a mianowicie Client Credentials. Jest to niewątpliwie prawda, ale takie podejście nieco ułatwiłoby implementację klienta, a przecież w wyzwaniach technicznych niekoniecznie o to chodzi. Gdyby klient po prostu prosił o token i otrzymywał go w odpowiedzi, można by obejść się bez użycia asynchroniczności, co z pewnością uszczupliłoby potencjał tego zadania jako sprawdzającego umiejętności programisty.
Na pierwszy ogień – serwer zasobów
Jako że lubię szybko dochodzić do rozwiązań, które działają, implementację rozpocząłem od napisania serwera zasobów. Póki co z zupełnie pomijamy kontrolę dostępu, więc po paru chwilach otrzymujemy coś w tym stylu:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
from aiohttp import web from datetime import datetime from time import time class TimeServer(web.Application): def __init__(self): web.Application.__init__(self) self.configure_routes() def configure_routes(self): self.router.add_route('GET', '/current_time', self.current_time) self.router.add_route('GET', '/epoch_time', self.epoch_time) async def current_time(self, request): return self.prepare_response(str(datetime.now())) async def epoch_time(self, request): return self.prepare_response(int(time())) def prepare_response(self, value): return web.json_response({"time": value}, status=200) if __name__ == '__main__': port = 9002 app = TimeServer() web.run_app(app, port=port) |
Po uruchomieniu możemy przetestować jego działanie np. przy użyciu curla:
|
1 2 3 4 |
$ curl localhost:9002/current_time {"time": "2019-12-06 21:51:54.763976"} $ curl localhost:9002/epoch_time {"time": 1575665518} |
Jest to dokładnie taki rezultat, jaki będziemy chcieli otrzymać finalnie, z tą różnicą, że zamiast uderzać bezpośrednio do serwera zasobów (który wtedy powinien zwrócić nam błąd HTTP 401), będziemy wysyłali zapytanie do klienta, który za naszymi plecami wykona wszystkie tricki związane z autoryzacją, po czym zwróci nam odpowiedzi które sam otrzymał od serwera zasobów. A to oznacza, że przed nami jeszcze trochę kodu do napisania!
Pocieszenie jest takie, że w samym serwerze zasobów niewiele się już zmieni (pomijając kwestie refaktoryzacji). Po otrzymaniu zapytania serwer powinien sprawdzić nagłówek Authorization i poprosić serwer autoryzacyjny o weryfikację znajdującego się tam tokena. W odpowiedzi dostanie zaś informację o sukcesie bądź niepowodzeniu walidacji oraz scope tokena – jeśli jest on prawidłowy (tzn. klient zgłosił się z tokenem odpowiadającym zasobowi o jaki prosi), to bez zbędnej filozofii zwracamy odpowiedź zawierającą czas.
Asynchroniczny klient
Ze względu na flow – Authorization Code – tutaj czeka nas znacznie więcej zabawy. Potrzebujemy bowiem zaimplementować następującą logikę:
- Aplikacja uruchamia serwer i nasłuchuje, czekając na zapytania od użytkownika
- Po otrzymaniu zapytania wysyła do serwera autoryzacyjnego prośbę o kod, przesyłając mu żądany scope, swoje ID oraz URL na jakim spodziewa się otrzymać callback
- Oczekuje aż serwer autoryzacyjny prześle żądanie zawierające kod autoryzacyjny
- Po otrzymaniu kodu wysyła kolejne zapytanie do serwera autoryzacyjnego, tym razem dołączając kod oraz swój sekret (client secret).
- W bezpośredniej odpowiedzi na powyższe zapytanie serwer powinien wreszcie dostarczyć nam upragniony access token.
- Z tymże tokenem aplikacja wysyła żądanie do serwera zasobów, a otrzymaną odpowiedź zwraca do użytkownika, który skontaktował się z nami w punkcie 1.
Jedno jest pewne – przy takim flow trzeba posłużyć się technikami takimi jak asynchroniczność lub wielowątkowość, skoro w trakcie obsługiwania jednego żądania (od użytkownika) musimy odebrać inne (z kodem od serwera autoryzacyjnego), a otrzymane dane wykorzystać przy pierwszym z nich.
Osobiście zdecydowałem się na użycie modułów aiohttp, asyncio oraz requests_async. Posługując się obiektem asyncio.Event mogłem w ten sposób oczekiwać na otrzymanie zapytania z kodem autoryzacyjnym:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
async def retrieve_token(self, scope): received_token_event = self._create_token_event(scope) await self.send_authorization_code_request(scope) await wait_for(received_token_event, AuthorizationProxy.RECEIVE_TOKEN_TIMEOUT_SEC) if scope not in self.token_values: return None return self.token_values[scope].pop() def _create_token_event(self, scope): event = asyncio.Event() self._push_into_dict(self.token_events, scope, event) return event def _push_into_dict(self, dict_object, key, value): if key not in dict_object: dict_object[key] = [value] else: dict_object[key].insert(0, value) |
Wspomniany wcześniej Event posiada metodę wait(), która pozwala na czekanie, aż ktoś inny wywoła na tym samym obiekcie metodę set(), jednak ponieważ chciałem, aby nie było to oczekiwanie potencjalnie trwające w nieskończoność, obudowałem ją w taką oto funkcję:
|
1 2 3 4 5 6 |
async def wait_for(event, timeout): try: await asyncio.wait_for(event.wait(), timeout) except asyncio.TimeoutError: pass return event.is_set() |
Podsumowując, eventy służące do powiadamiania o otrzymaniu tokena znajdują się w słowniku token_events, zaś wartości samych tokenów w podobnym obiekcie o nazwie token_values. Oba te słowniki są indeksowane nazwami scope’ów. W taki zaś sposób posługuje się nimi metoda odpowiedzialna za obsługę żądania wpływającego od serwera autoryzacyjnego:
|
1 2 3 4 5 6 7 8 9 |
async def handle_auth_callback(self, request): scope = request.query.get('scope', None) code = request.query.get('code', None) response = await self.send_token_request(code) token = response.json()['access_token'] self._push_into_dict(self.token_values, scope, token) if scope: self.token_events[scope].pop().set() |
W powyższych fragmentach pomijam otoczkę związaną ze sprawdzaniem błędów, aby nie zaciemniać samej idei. Całość pliku, o którym mowa można zobaczyć pod tym linkiem.
Ostatnia część, czyli serwer autoryzacjny
Tym oto sposobem dochodzimy wreszcie do serwera autoryzacyjnego. Tu nie musimy już myśleć o asynchronicznych zdarzeniach, jednak mamy na głowie kilka innych zagadnień, spośród których na pierwszy plan wybijają się dwa:
- Generowanie i walidacja tokenów
- Weryfikacja danych klienta
Tak jak zostało to zasugerowane w treści zadania, użyjemy tokenów JWT. Posiadają one tę zaletę, że wszelkie potrzebne nam dane o takim tokenie, tj. czas jego wygaśnięcia oraz scope możemy zakodować wewnątrz niego samego. Dzięki temu odpada nam konieczność użycia bazy danych do ich przechowywania. Kiedy serwer zasobów poprosi o weryfikację tokena, serwer autoryzacyjny odkoduje go sobie (ponieważ tylko on zna „hasło” potrzebne do jego zakodowania i odkodowania) i sprawdzi jego ważność.
Baza danych (ja wybrałem SQLite) i tak jednak stanie się częścią tej implementacji, a to za sprawą potrzeby przechowywania informacji o zarejestrowanych klientach. Wprawdzie sama rejestracja nie była konieczna do zaimplementowania, ale założyliśmy, że dane jednego klienta, tzn. jego id oraz secret są serwerowi znane. Należy przy tym pamiętać, że client secret, podobnie jak jakiekolwiek inne hasła, ze względów bezpieczeństwa nie mogą być zapisane w bazie jawnym tekstem. Do bazy wrzucamy zatem tylko wyliczony hash, co wystarczy nam, aby zweryfikować czy proszący o tokena klient dostarcza poprawne dane.
Same kody autoryzacyjne (czyli te, które są generowane przez serwer po pierwszym zapytaniu wysłanym przez klienta) możemy natomiast spokojnie zapisywać w pamięci operacyjnej. Zazwyczaj nadaje im się dość krótki czas życia (nawet rzędu kilku sekund), więc nie musimy się martwić przechowywaniem ich dużej ilości. Ja dodatkowo zaimplementowałem metodę, która po przekroczeniu pewnego progu wykonuje czyszczenie niewykorzystanych kodów, które już wygasły (zob. w kodzie)
O czym jeszcze warto pamiętać? Wymieniłbym tu następujące kwestie:
- Każdy kod autoryzacyjny powinien być móc użyty do wygenerowania tokenu tylko raz
- Jeśli klient zgłasza się z kodem, to należy sprawdzić, czy jest to kod, który został przydzielony właśnie temu konkretnemu klientowi
Szlifowanie
Kiedy już wszystkie trzy komponenty zostały ukończone, przyszedł czas na niezbędne poprawki i ulepszenia, tj.:
- Zmiana protokołu komunikacji między poszczególnymi serwerami z HTTP na HTTPS – bezpieczniej jest, aby wrażliwe dane nie latały po sieci bez żadnego szyfrowania.
- Dockeryzacja – nie ma to jak móc postawić cały projekt jednym prostym
docker-compose up - Refaktoryzacja – niezbędne uporządkowanie kodu, np. kompetencją samego serwera zasobów powinna być jedynie obsługa żądań, a nie dostarczanie danych biznesowych (w tym przypadku banalne wyliczanie czasu)
- Logowanie – usuwamy zbędne printy i zastępujemy je bardziej profesjonalnymi loggerami, dostosowując przy tym poziom logów (info, warning, error itd.) do ich rzeczywistej ważności.
- Testy – nawet jeśli ktoś nie wspomina o testach, to uważam że błędem byłoby ich nie dostarczyć, nawet jeśli miałyby one być w jakiejś szczątkowej formie, służące za przykład i dowód pamiętania o nich.
Jeżeli powyższy artykuł w jakiś sposób Wam się przysłużył – bardzo mi milo! Jeśli zaś jego lektura nasunęła Wam na myśl jakieś uwagi lub merytoryczną krytykę- śmiało piszcie!
