Kiedy półtora roku temu dołączałem do nowego zespołu programistycznego, sądziłem, że będę kodować przede wszystkim Pythonie. Liczyłem się też z ewentualnością pisania co nieco w JavaScripcie, bo przecież język ten jest aktualnie wszechobecny, ale zupełnie nie spodziewałem się, że dane mi będzie… programować graficznie. W Apache NiFi. I na dodatek zostać swego rodzaju zespołowym ekspertem w tej technologii. Posłuchajcie mojej historii pełnej przygód i wyzwań, jak również irytacji, zniecierpliwienia i wreszcie zadowolenia z dobrze wykonanej pracy i rozwiązanych problemów.
Na wstępie zaznaczę, że bynajmniej nie jestem fanem programowania graficznego. Zdecydowanie wolę kod i słowo pisane, aniżeli UI-owe narzędzia, nawet jeśli prezentują się bardzo ładnie. I kiedy jestem zmuszony tworzyć algorytmy nie słowem, lecz kliknięciami myszki, czuję, że moja wydajność spada.
Gdy zatem przy okazji wykonywania któregoś ze swoich pierwszych tasków dowiedziałem się, że w projekcie używane są narzędzia takie jak NiFi oraz MiNiFi, pierwszym działaniem jakie podjąłem, było wypytywanie innych pracujących ze mną programistów o szczegóły i próba skonsultowania z nimi napotkanych problemów. Niestety. Okazało się, że właściwie nikt z zespołu deweloperskiego nie może poszczycić się rozległą wiedzą w zakresie NiFi. I w ten oto sposób, trochę metodą prób i błędów, trochę przy pomocy internetowego researchu i grzebania w oficjalnej dokumentacji, wykonałem swoje pierwsze zadanie w tej technologii. A potem kolejne i kolejne. I jeszcze kolejne. Aż pewnego dnia stało się oczywiste, że gdy pojawia się NiFi-owy problem, to jestem pierwszym kandydatem do jego rozwiązania.
Spis treści
NiFi – co to w ogóle jest?
Ale, ale – czym w ogóle jest ten cały NiFi? Co należy o nim wiedzieć oprócz tego, że wiąże się z programowaniem graficznym? Historia tego projektu jest dość ciekawa, bowiem narodził się on amerykańskiej National Security Agency i początkowo funkcjonował pod nazwą Niagarafiles, która przy późniejszym opublikowaniu została przemianowana na NiFi (wymawiać podobnie jak WiFi) [1]. Miała ona oczywiście nawiązywać do ogromnych ilości strumieni danych, których przetwarzaniem zajmowało się to właśnie oprogramowanie.
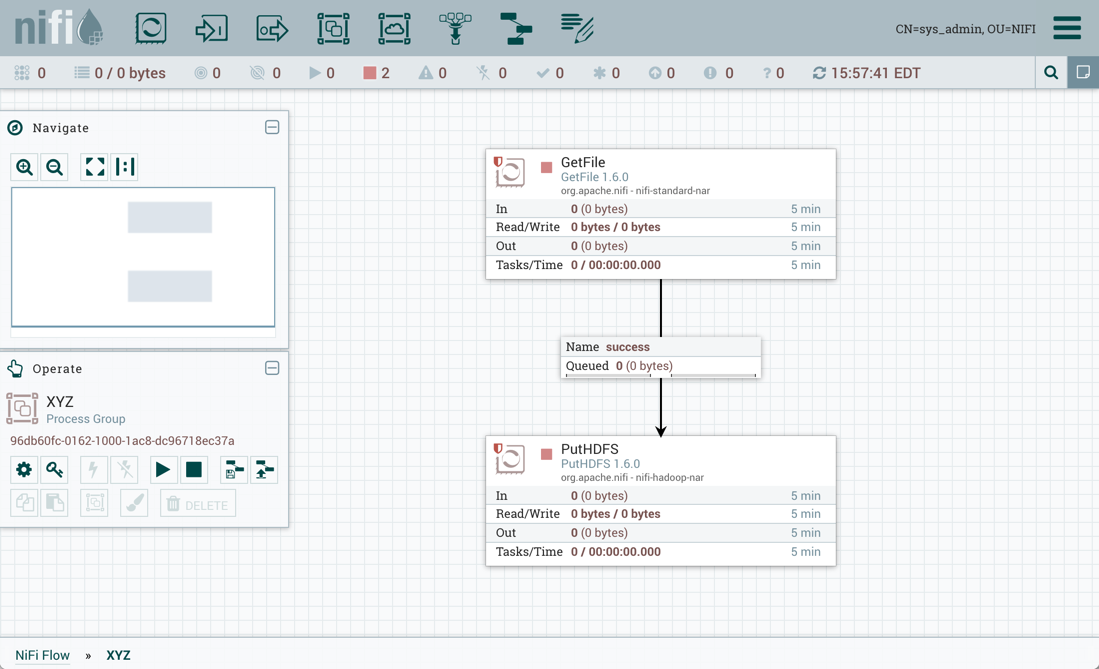
Sterowanie danymi odbywa się przy pomocy tworzenia przepływów (ang. flows). Ich podstawę stanowią komponenty odpowiedzialne za wykonywanie wydzielonych zadań (takich jak zapis do/odczyt z pliku lub bazy danych, odebranie requestu, czy dzielenie/scalanie danych) – są to tak zwane procesory. Można łączyć je ze sobą, a także grupować, zaś wszystko to odbywa się przy pomocy webowego interfejsu graficznego (zrzut ekranu poniżej).
Więc co tak naprawdę potrafi NiFi? Według oficjalnej strony projektu, jest to „łatwy w użyciu, wydajny i niezawodny system do przetwarzania i dystrybucji danych” [2]. Czyli nie tylko przetwarza dane, ale dodatkowo robi to wydajnie i niezawodnie, zaś jego obsługa jest prosta. Tyle mówi teoria. W praktyce okazuje się niestety, że owa łatwość używania nie zawsze jest idealna i czasami trzeba się naprawdę nieźle nagimnastykować. A zatem posłuchajcie o przykładowych problemach, które udało mi się napotkać w ciągu ostatnich miesięcy.
Registry i wersjonowanie zmian
Tworzone przepływy danych mogą być oczywiście wersjonowane – commitowanie zmian, podobnie jak ich wprowadzanie, również odbywa się z poziomu webowego UI, a informacje o wersjach trafiają do narzędzia o nazwie NiFi Registry. I w tym miejscu pojawia się pierwszy problem. Registry to nie git, więc jeżeli zespół programistyczny posiada ustalony proces dostarczania funkcjonalności oparty o gita, peer code review, tworzenie branchy, mergowanie ich, związane z tym CI/CD itd., to fragment systemu oparty o NiFi będzie stanowił wyjątek, który należy obsłużyć w inny sposób.
Jaki? W Registry nie istnieje pojecie gałęzi (ang. branches), więc chcąc odseparować produkcyjną wersję naszego oprogramowania od tej w fazie rozwoju należy po prostu użyć dwóch różnych instancji rejestru. Review? Można np. udostępniać pozostałym programistom link do nowej wersji flow, aby mogli go po prostu obejrzeć.
Nie brzmi idealnie? Dla mnie też nie brzmiało, dlatego pokusiłem się o skonfigurowanie NiFi Registry w taki sposób, aby do przechowywania wszystkich archiwalnych i bieżących wersji przepływów wykorzystywało gita. W dokumentacji wyczytałem, że istnieje wbudowane rozwiązanie, pozwalające na dokonanie takiej zmiany – GitFlowPersistenceProvider. Super! Niestety już podczas pierwszych testów okazało się, że owo persistence jest raczej słabe i nijak ma się do tego, co tak pięknie zostało przedstawione w dokumentacji.

Mianowicie po stworzeniu nowej instancji Registry i skonfigurowaniu jej tak, aby używała tego samego repozytorium gitowego, do którego zapisywała dane wcześniejsza instancja rejestru okazało się, że… żadne przepływy nie zostały przywrócone! Skonfundowany udałem się skonsultować tę kwestię na StackOverflow, gdzie dowiedziałem się, iż rzeczywiście funkcjonalność ta może aktualnie nie działać tak jak trzeba. Do poprawnego odtworzenia stanu poprzedniego potrzebne są bowiem nie tylko pliki reprezentujące poszczególne flowy, ale również plik bazy danych, w dużej mierze duplikujący te informacje i nie podlegający automatycznemu wrzucaniu do gita. W tej sytuacji nie pozostało mi nic innego, jak dodać do crona skrypt, automatycznie wrzucający bazę danych do repozytorium. Tylko czy rzeczywiście tak powinno to wyglądać?
Co więcej, nie był to jedyny problem, jakiego doświadczyłem, używając NiFi Registry. Kolejny raz kiedy moje zdziwienie sięgnęło zenitu miał miejsce gdy po godzinach debugowania okazało się, iż scommitowanie pod Windowsem process groupy, która w swoim wnętrzu zawiera inną wersjonowaną process groupę, skutkuje tym, że taki przypływ można zaimportować wyłącznie na NiFi działające na Windowsach. Natomiast instancje uruchomione na maszynach z Linuksem oraz Registry zupełnie nie radziły sobie z takim przypadkiem, rzucając dokoła dziwnymi błędami. Wniosek? Nawet jeśli NiFi przetwarza dane niezawodnie, to NiFi Registry zbyt dużą niezawodnością bynajmniej nie może się poszczycić.
Ograniczone MiNiFi
Podczas swojej kariery „NiFi-owego eksperta” miałem też okazję pracować z bardziej minimalistyczną wersją tego narzędzia – Apache MiNiFi. Charakteryzuje się ona przede wszystkim brakiem interfejsu graficznego. Oznacza to, że wszystkie przepływy należy rozwijać wewnątrz NiFi UI, a następnie eksportować do akceptowanych przez MiNiFi plików .yml (co swoją drogą też nie należy do najprzyjemniejszych – zamiast jednego kliknięcia, należy zrobić ich o wiele więcej, najpierw tworząc template na podstawie flow, później eksportując do do .xml, a na samym końcu, używając kolejnej javowej paczki – MiNiFi Toolkit – skonwertować do .yml).
Oprócz tego MiNiFi posiada też trochę innych ograniczeń, które sprawiają, że przez próbę ich obejścia względnie proste przepływy zaczynają niekiedy stawać się coraz bardziej udziwnione. Pozwolę sobie wymienić tu dwa, które przysporzyły mi najwięcej „zabawy”:
- brak możliwości używania variable registry – rejestru zmiennych dostępnych wewnątrz całego przepływu lub process groupy
- brak możliwości korzystania z liczników
Drugie z tych ograniczeń sprawiło, że kiedy chciałem zaimplementować w MiNiFi monitoring używanego w projekcie przepływu, musiałem uciec się do stworzenia zewnętrznego skryptu, przechowującego liczniki w bazie danych, który z odpowiednimi argumentami był wywoływany z poziomu MiNiFi.
Testowanie
Jak wiadomo, testowanie jest istotnym i nieodłącznym elementem procesu wytwarzania oprogramowania. Tak, teoretycznie wiadomo, ale w przypadku NiFi testowanie było prawdziwą udręką, przynajmniej na początkowym etapie rozwoju projektu. Dlaczego? Ponieważ brakowało automatyzacji i wymagana była ręczna weryfikacja wszystkich wprowadzanych zmian, co w przypadku przepływów o sporych rozmiarach, powodowało konieczność poświęcenia jeszcze większej ilości czasu.

NiFi dostarcza jakieś wbudowane rozwiązania służące do pewnej automatyzacji testów, ale przede wszystkim dotyczą one testów customowych procesorów, nie zaś całych grup. Aby rozwiązać ten problem, zastosowaliśmy w naszym projekcie dwa rozwiązania:
- Ja zacząłem od stworzenia zestawu testów (w pythonowym unittest), które wchodziły w interakcję w NiFi przy pomocy protokołu HTTP. Było to możliwe do zrealizowania, ponieważ w naszym przypadku wiele przepływów rozpoczynało się od nasłuchiwania żądań.
- Po jakimś czasie kolega z zespołu wykonał świetną robotę, tworząc mini-framework do automatycznego testowania przepływów, bazujacy na bibliotece nipyapi (również z wykorzystaniem unittest). Idea była prosta – w teście definiowane były nazwy bucketów i flowów oraz adres zdalnego repozytorium (NiFi Registry), zaś framework pobierał je z niego i umieszczał na „płótnie” (ang. canvas). Następnie tworzył komponenty generujące nowy flowFile wraz z atrybutami określonymi w teście i łączył je z wejściem testowanego przepływu. Jego wyjście było zaś łączone z wygenerowanym przez framework komponentem, zapisującym zawartość flowFile’a do pliku.
Zdaję sobie sprawę, że powyższy opis zastosowanego rozwiązania jest zapewne niezrozumiały dla osób nie siedzących w temacie NiFi, ale a nuż przyda się komuś, borykającemu się z podobnym co my problemem.
Podsumowanie
Co z perspektywy czasu sądzę o swojej NiFi-owej przygodzie? Przede wszystkim cieszę się, że miałem okazję zdobyć to doświadczenie. Praca z nieznanymi mi wcześniej technologiami zawsze jest czymś, co bardzo cenię. Spotkałem gamę problemów, których zapewne nie napotkałbym gdzie indziej (mam tu na myśli zarówno programowanie graficzne, jak i niską popularność tego narzędzia), a to wszak poszerza moje umiejętności rozwiązywania kolejnych. Czy rozważałbym w przyszłości pracę z użyciem NiFi? Na pełen etat – definitywnie nie. Częściowo – niewykluczone. 😉
Linki i źródła
- Niagarafiles Keep Data Flowing, National Security Agency.
- Apache NiFi – strona oficjalna.
- Apache NiFi User Guide.
