Śmiało można rzec, że paradygmat programowania obiektowego jest obecnie najpopularniejszym i najpowszechniej używanym. Większość języków głównego nurtu, jak chociażby C++, Java, Python, C# czy JavaScript, pozwala na tworzenie oprogramowania właśnie w sposób obiektowy. Co więcej, paradygmat ten ma już swoje lata, bowiem pierwszy język obiektowy powstał już ponad 50 lat temu (pisałem o tym w artykule Simula – narodziny programowania obiektowego).
Wydawać by się więc mogło, że obecnie wszyscy programiści są już dobrze zaznajomieni z tzw. „obiektówką” i trudno jest zaskoczyć ich czymś nowym w tym względzie. Klasy, prototypy, dziedziczenie, polimorfizm, hermetyzacja – te pojęcia są na ogół dobrze znane, ale czy na pewno zawsze prawidłowo wykorzystujemy idee za nimi stojące?
Obserwując powstający kod, niekiedy można pokusić się o stwierdzenie, że jedyne, co ma on wspólnego z obiektowością, to użycie klas, zaś jego charakter bardziej przypomina programowanie proceduralne. Zwrócił na to uwagę między innymi Junade Ali, autor książki „Mastering PHP Design Patterns” (tłum. za Wiki):
Programowanie obiektowe to więcej niż klasy i obiekty; to cały paradygmat programowania bazujący na obiektach (strukturach danych), które zawierają obszary danych (pola) oraz metody. Zrozumienie tego jest bardzo ważne; używanie klas do zorganizowania zbioru niezwiązanych ze sobą metod nie jest podejściem obiektowym.
Przykład takiego po części obiektowego, a po części proceduralnego kodu można znaleźć w artykule „OOP vs Procedural Code” Anthony’ego Ferrary, w którym autor prezentuje swój pogląd na programowanie obiektowe (w pewnych miejscach nieco kontrowersyjny, o czym świadczy np. dyskusja na Hacker News).
Abstrahując od oceny tego, czy ten sposób programowania jest dobry czy zły, możemy zadać sobie pytanie: dlaczego w ogóle taki kod powstaje? Moją odpowiedzią jest: bo może. Wymienione wcześniej języki programowania wspierają wprawdzie paradygmat obiektowy, ale nie tylko. Są one wieloparadygmatowe, a zatem programista może w nich z dużą dowolnością wykorzystywać różne podejścia. Języki te nie narzucają konkretnego paradygmatu i pozwalają na odstępstwa od ścisłych reguł.
Istnieją jednak języki, które takiej swobody nie dają i w sposób bardzo restrykcyjny implementują tylko jeden paradygmat programowania. Jest ich zdecydowanie mniej i nie cieszą się aż taką popularnością, ale uczenie się ich i pisanie w nich dostarcza wielu korzyści (więcej o tym przeczytacie w kolejnym wpisie) oraz potrafi dać sporo frajdy.
Spis treści
Czysto obiektowy Smalltalk
Jednym z garstki czysto obiektowych języków programowania jest Smalltalk. Jest też pierwszym z nich (został stworzony w roku 1972 przez zespół Alana Kaya), aczkolwiek cała arcyciekawa historia tego języka to znów temat na osobny artykuł, więc tym razem nie będę się więcej na ten temat rozwodził. Smalltalk jest również technologią, która dostarczyła informatyce wielu ważnych pomysłów: wzorzec MVC, nowoczesne IDE, kompilacja just-in-time, maszyna wirtualna języka, eXtreme programming, TDD – to tylko niektóre z konceptów, które zostały zapoczątkowane w Smalltalku.
Zanim przejdziemy do tego, co w Smalltalku najciekawsze i najdziwniejsze zarazem, pozwolę sobie jeszcze doprecyzować jedną istotną kwestię. Otóż obecnie mianem Smalltalka nie określa się zazwyczaj żadnego konkretnego języka, ale całą ich grupę, której przedstawiciele nazywani są dialektami Smalltalka. Oryginalny Smalltalk, którego kolejne wersje były oznaczane jako Smalltalk-72, Smalltalk-76 i Smalltalk-80 obecnie nie jest już rozwijany, ale posiada wielu żyjących spadkobierców, zarówno otwartoźródłowych, jak i komercyjnych.
Najpopularniejsze dialekty to Squeak (jednym z jego autorów jest sam Alan Kay, twórca oryginalnego Smalltalka), Pharo, VisualWorks i GNU Smalltalk. Większość najważniejszych cech Smalltalka jest obecna we wszystkich tych dialektach i to właśnie te właściwości języka przedstawię w tym artykule. Zaznaczam jednak, że wszelkie fragmenty kodu oraz ilustracje będę pokazywał na przykładzie Squeaka, jako jednej z najbardziej ortodoksyjnych współczesnych implementacji.
Prostota syntaktyczna
Składnia Smalltalka jest tak prosta, że można by nawet nazwać ją banalną. Istnieje zaledwie 6 słów kluczowych:
- self – odnosi się do odbiorcy aktualnie wykonywanej metody i działa podobnie jak
selfw Pythonie lubthisw C++ - super – wskazuje na instancję klasy nadrzędnej, podobnie jak ma to miejsce w innych językach
- nil – obiekt niezdefiniowany
- true – unikalna instancja klasy
True - false – unikalna instancja klasy
False - thisContext – wskazuje na ramkę ze szczytu stosu
Wszystko oprócz nich to obiekty, posiadające metody zwane w Smalltalku wiadomościami (ang. messages). Hm, a liczby? Czy nie są przypadkiem prymitywami? Nie w Smalltalku, tutaj są one pełnoprawnymi obiektami, do których można wysyłać wiadomości. Spójrzmy na poniższy fragment kodu:
|
1 2 3 4 5 6 7 |
1 class "SmallInteger" 1234567890123456789 class "LargePositiveInteger" 3.14 class "SmallFloat64" 2 class superclass "Integer" 2 class superclass superclass "Number" -0.3 class superclass superclass "Number" |
Tekst w cudzysłowach to komentarze (tak oznacza się je w Smalltalku), w których wpisałem wynik, jaki otrzymamy jeśli wykonamy każą z linii, drukując przy tym otrzymany wynik. Pisząc 1 posługujemy się instancją klasy SmallInteger, a 1 class oznacza wysłanie wiadomości class do tego obiektu. Akurat ta wiadomość (metoda) jest zaimplementowana w jednej z klas nadrzędnych (konkretniej, w klasie Object).
W tym miejscu możemy zatem przejść do wiadomości, których są jedynie trzy rodzaje:
- unarne – posiadają tylko jeden argument, np.
3 squared - binarne – przyjmują dwa argumenty, np.
2 + 2 - ze słowami kluczowymi (ang. keyword messages) – używają dowolnej liczby słów kluczowych; po każdym z nich występuje dwukropek, np.
16 printOn: Transcript base: 2
I to właściwie wszystko. Składnia jest tak prosta, że w ogóle nie trzeba obciążać swojej pamięci. Zaczynając używać Smalltalka trzeba się natomiast przygotować na to, że pierwsze kroki będą polegały przede wszystkim na wyszukiwaniu interesujących nas obiektów i ich wiadomości, a nie na szukaniu konstrukcji językowych, których należy użyć. Warto też mieć w głowie 5 głównych zasad modelu obiektowego w Smalltalku:
- Wszystko jest obiektem
- Każdy obiekt jest instancją klasy
- Każda klasa ma klasę nadrzędną
- Wszystko dzieje się przez wysyłanie wiadomości
- Wyszukiwanie metod używa łańcucha dziedziczenia
Definiowanie klas i metod
Pisząc w popularnych językach, jesteśmy przyzwyczajeni, że tworzenie nowej klasy odbywa się przy użyciu jakiejś specjalnej składni, zazwyczaj wykorzystującej słowo kluczowe class. Smalltalk idzie oczywiście pod prąd i utworzenie klasy polega zwyczajnie na wysłaniu wiadomości do klasy nadrzędnej. Zerknijmy np. jak tworzona jest klasa Fraction, która reprezentuje ułamek:
|
1 2 3 4 5 |
Number subclass: #Fraction instanceVariableNames: 'numerator denominator' classVariableNames: '' poolDictionaries: '' category: 'Kernel-Numbers' |
Wiadomość, która jest wysyłana do klasy nadrzędnej Number to keyword message z pięcioma słowami kluczowymi. Przekazujemy w niej nazwę naszej nowej klasy oraz ewentualne pola (klasowe i obiektowe), a także słowniki (służące do współdzielenia zmiennych między klasami) i kategorię. W Smalltalku każda klasa należy do jakiejś kategorii. Te związane z liczbami, które znajdują się w naszych przykładach przynależą domyślnie do kategorii Kernel-Numbers, która zawiera między innymi takie klasy jak Number, Integer, Float, Random, a także ich klasy pochodne.
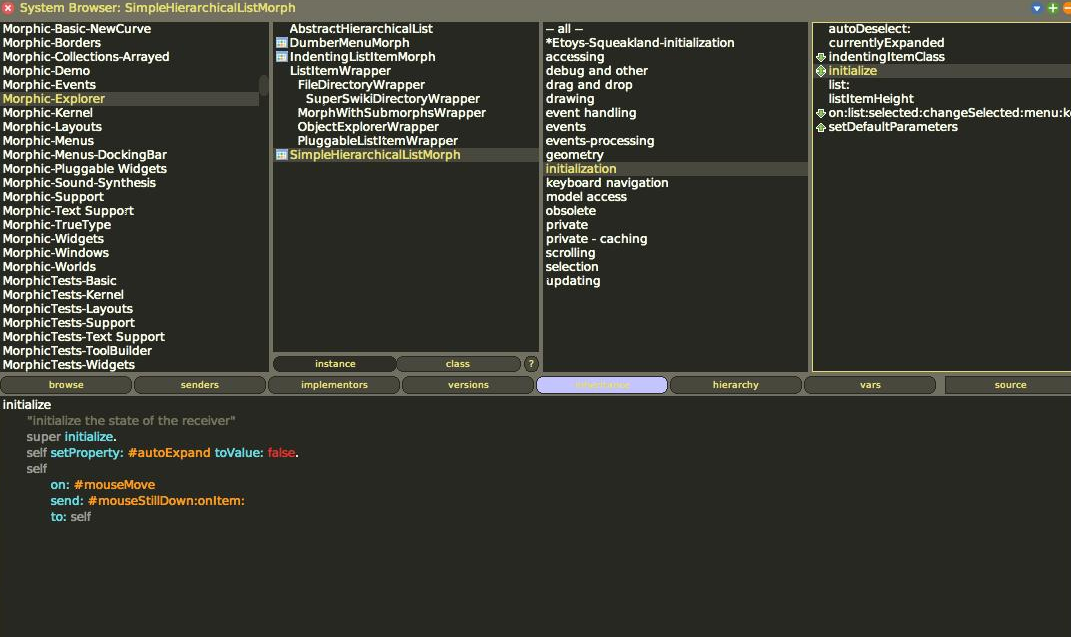
Wysłanie wiadomości tworzącej klasę odbywa się w specjalnym elemencie IDE nazywanym przeglądarką (o czym będzie później). Tam też należy wstawiać definicje wiadomości, również przypisując je do odpowiednich kategorii. Żeby mieć wreszcie jakieś pojęcie o tym, jak wyglądają te słynne wiadomości, sprawdźmy kilka zaimplementowanych w klasie Integer:
|
1 2 |
asHexDigit ^ '0123456789ABCDEF' at: self + 1 |
|
1 2 3 4 5 |
timesRepeat: aBlock | remaining | remaining := self. [ (remaining := remaining - 1) >= 0 ] whileTrue: [ aBlock value ] |
Pierwsza z nich pozwala wyświetlić liczbę dziesiętną z zakresu 0-15 jako cyfrę w zapisie heksadecymalnym. Jak widać, sama implementacja jest nadzwyczaj prosta i sprowadza się do wzięcia z łańcuchu znaków elementu z określonego indeksu i zwrócenia go. W Pythonie moglibyśmy zapisać ten kod jako:
|
1 2 |
def asHexDigit(n): return "0123456789ABCDEF"[n] |
Dostrzegacie już pewną ważną różnicę (oprócz tego, że zamiast słowa return używa się znaku ^) między tymi fragmentami kodu? W Pythonie używamy indeksu n, zaś w Smalltalku self + 1. Dlaczego? Ponieważ Smalltalk należy do nielicznej grupy języków programowania, w których indeksowanie rozpoczyna się nie od zera, ale od jedynki.
Nie mniej ciekawy jest drugi ze snippetów. Wiadomość timesRepeat: przyjmuje jeden argument, który, zgodnie ze swoją nazwą, powinien być blokiem kodu. Następnie definiuje zmienną lokalną remaining i dopóki jej wartość jest większa lub równa zero, blok kodu jest ewaluowany (aBlock value). Oznacza to, że wiadomości tej można użyć np. w taki sposób:
|
1 |
5 timesRepeat: [Transcript showln: 'Hello'] |
co poskutkuje wyświetleniem (na tzw. transkrypcie) napisu „Hello” i znaku nowej linii pięciokrotnie. Czyż temu zapisowi można odmówić czytelności? A jest to zwyczajnie wygodne obudowanie pętli, wykonującej zadany blok kodu N razy.
Instrukcje sterujące
I tym sposobem dochodzimy do ważnej dla każdego programisty kwestii instrukcji sterujących. Kiedy uczymy się nowego języka, to zazwyczaj jedną z pierwszych rzeczy, jakich chcemy się dowiedzieć, to jak stosować w nim pętle i instrukcje warunkowe. Smalltalk i tym razem ukazuje nam, że zastosowane w nim podejście jest wyjątkowe na tle innych technologii. Nie ma tu żadnego odstępstwa od wspomnianej już zasady „wszystko dzieje się przez wysyłanie wiadomości”. Napisanie if-else albo pętli jest zatem realizowane przez zwykłe wysyłanie wiadomości do obiektów i nie ma potrzeby wprowadzania żadnych specjalnych konstrukcji składniowych. Oto szlacheta smalltalkowa prostota!
Ok, zastanówmy się w takim razie do jakiego obiektu wysyłać owe wiadomości. Jeśli chodzi o pętle, to karty zostały odkryte już w poprzednim przykładzie kodu. whileTrue: jest tam wywoływane na obiekcie [ (remaining := remaining -1) >= 0]. Nawiasy kwadratowe oznaczają, że mamy do czynienia z blokiem kodu, czyli obiektem klasy BlockClosure. Argumentem, który przyjmuje ta wiadomość jest kolejny blok kodu. Żeby uczynić nasz przykład nieco bardziej zrozumiałym, można by go też trochę przeformatować:
|
1 2 3 |
[remaining > 0] whileTrue: [aBlock value. remaining := remaining - 1] |
Wiadomości pozwalające na warunkowe wykonanie kodu są natomiast zaimplementowane jako metody klasy Boolean. W Smalltalku możemy więc wykonać np. taki kod:
|
1 2 3 4 |
x := 10. x < 5 ifTrue: [Transcript showln: 'Correct'] ifFalse: [Transcript showln: 'Wrong'] |
Obrazy, nie pliki
Kolejną bardzo specyficzną dla Smalltalka cechą jest to, że nie bazuje on na plikach (ang. file-based), ale na obrazach (ang. image-based). Tworząc aplikację raczej nie zapisujemy więc naszego kodu źródłowego w plikach tekstowych, jak ma to miejsce w większości języków programowania, ale zapisujemy stan obrazu, na którym pracujemy. Obrazy te są uruchamiane na smalltalkowej maszynie wirtualnej (która jest przodkiem takich technologii jak choćby JVM).
Obraz zawiera stan wszystkich istniejących obiektów, w tym również informacje o otwartych strumieniach, położeniu poszczególnych okien w IDE, czy aktualnie uruchomionym debuggerze. Sam obraz jest już oczywiście zapisywany jako plik (zazwyczaj z rozszerzeniem .image), a ponadto wszelkie zachodzące w nim zmiany są przechowywane w skojarzonym z nim pliku .changes. Konsekwencja tego, że domyślne obrazy nowoczesnych implementacji Smalltalka (np. Pharo czy Squeaka) powstają przez modyfikowanie wcześniej istniejących obrazów jest bardzo ciekawa. Otóż do istniejących obiektów wysyłane są wiadomości, które tworzą nowe klasy, dodają nowe funkcjonalności itd. W ten sposób nawet w dzisiejszych obrazach różnych dialektów Smalltalka bytują sobie obiekty, które zostały powołane do życia kilkadziesiąt lat temu (może nawet w 1972, przy pierwszym wydaniu języka).
Taka opierająca się na obrazach architektura to coś, do czego jako programiści z reguły nie jesteśmy przyzwyczajeni. Jest rozwiązaniem rewolucyjnym, choć, jak widać, nie przyjęła się, przez co po dziś dzień piszemy kod, zapisując go w zwykłych plikach – tak samo jak w czasach, kiedy powstawały pierwsze języki programowania. Mimo całej swojej dziwności, smalltalkowe obrazy mają całkiem sporo zalet. Nie pracujemy w edytorze, przeglądając składające się z dziesiątek lub setek linii kodu pliki, wyszukując w nich interesujące nas metody i obiekty. Zamiast tego, korzystamy z przeglądarki, która prezentuje poszczególne fragmenty kodu w poukładany i zhierarchizowany sposób.
Dzięki stosowaniu obrazów Smalltalk może poszczycić się tzw. live codingiem – wszystkie zmiany, które wprowadzamy, są od razu aplikowane, a ich efekty natychmiastowo widoczne. Jeśli nasz kod wygeneruje błąd i zostanie rzucony wyjątek, zawsze możemy przejść do debuggera i nawet z jego poziomu dokonać poprawek. Jest to tak wygodne rozwiązanie, że, jak głosi legenda, podobno niektórzy smalltalkerzy piszą całe aplikacje, nie wychodząc z debuggera. Co więcej – wyobraźmy sobie sytuację, w której podczas weryfikacji naszego programu przez testera leci jakiś krytyczny błąd. Tester nie musi sobie zaprzątać głowy żadnymi logami (które na dodatek nie zawsze zawierają informacje pomocne przy analizie przyczyny), tylko zapisuje bieżący obraz i przesyła go nam. Tym sposobem my otrzymujemy aplikację w dokładnie takim stanie, do jakiego doprowadził ją tester – możemy odpalić debugger, sprawdzić konkretne obiekty itd. Gdyby rozwiązywanie bugów zawsze wyglądało w ten sposób, to świat z pewnością byłby piękniejszy.
Bazowanie na obrazach ma też wpływ na sposób kontroli wersji i releasowania aplikacji. Gita lepiej odstawić w kąt (choć przy odpowiednim nagimnastykowaniu się, teoretycznie można z niego korzystać) i zapoznać się ze smalltalkowymi odpowiednikami. Jednym z nich jest Monticello – rozproszony system kontroli wersji przystosowany do pracy z obrazami, który zbiera całkiem dobre recenzje od swoich użytkowników. Z kolei chcąc wydać naszą aplikację, trzeba skorzystać z narzędzi, które pozwalają oczyścić obraz z wszelkich zbędnych elementów. Dodatkowo, niektóre implementacje Smalltalka udostępniają możliwość wygenerowanie pojedynczego pliku wykonywalnego.
Na koniec uspokajam osoby, które nie wyobrażają sobie życia bez plików tekstowych – w Smalltalku można oczywiście wyeksportować kod do zwykłych plików, zazwyczaj z rozszerzeniem .st i importować go z nich. Można, ale życie z obrazami jest naprawdę wygodne i warto się o tym przekonać.
IDE – środowisko bardzo zintegrowane
Ostatni element, o którym chciałbym co nieco opowiedzieć, to IDE. Stanowi ono nierozerwalną część Smalltalka – często jest zaimplementowane w nim samym, posiada multum przydatnych narzędzi developerskich i oczywiście działa wewnątrz maszyny wirtualnej. W Smalltalku uruchomienie obrazu jest w gruncie rzeczy tożsame z odpaleniem IDE (przynajmniej w większości przypadków). Oznacza to, że decydując się na konkretny dialekt Smalltalka, decydujemy się również na związane z nim środowisko programistyczne, gdyż żaden alternatywny sposób pisania kodu raczej nie będzie ani wygodniejszy ani wydajniejszy.
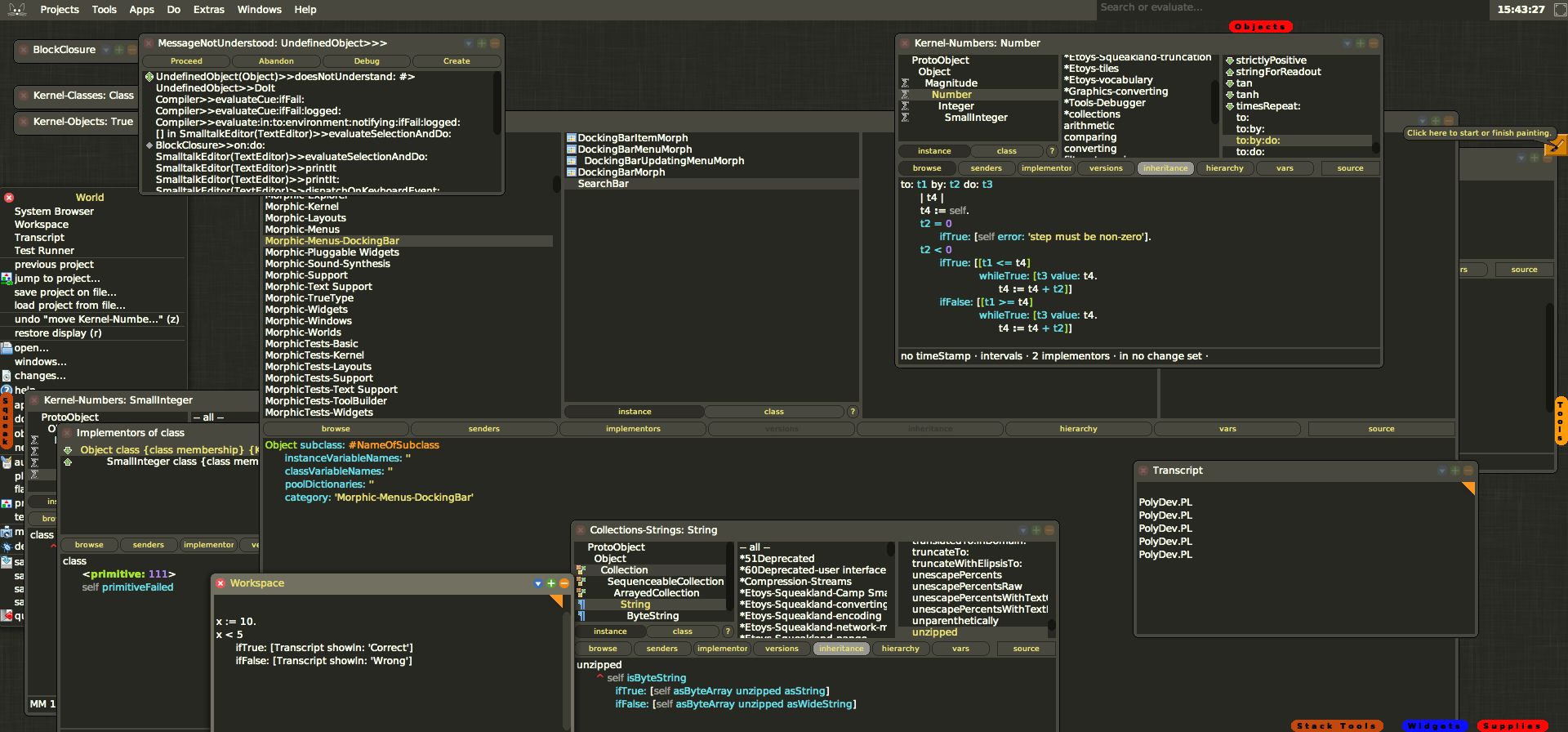
Najważniejsze komponenty w IDE Smalltalka to:
- System Browser – przeglądarka systemowa, czyli miejsce, w którym dzieje się najwięcej: tu tworzymy klasy i wiadomości
- Inspector oraz Explorer – narzędzia, dające nam wgląd w stan dowolnych obiektów, pokazujące przechowywane wewnątrz wartości, typ itd.
- Workspace – przestrzeń robocza. Tu manualnie testujemy nasz kod, wykonujemy go, poznajemy wartości interesujących nas wyrażeń
- Transcript – okno służące przede wszystkim jako miejsce, w którym drukowane są rezultaty naszych poczynań
- Debugger – implementuje standardowe funkcjonalności każdego debuggera, a dodatkowo pozwala na zmianę kodu „na żywo” podczas debuggowania
- SUnit – narzędzie do testów jednostkowych, a zarazem pierwszy w historii framework do testów jednostkowych.
Podczas pracy, programista może otwierać dowolną liczbę instancji każdego z tych komponentów. Okna można minimalizować, zmieniać ich rozmiar i dowolnie rozmieszczać jak na pulpicie. Rozwijanie oprogramowania w Smalltalku pozwala zanurzyć się w jego środowisku i długo z niego nie wychodzić. Wszystko co potrzebne mamy pod ręką, wystarczy tylko eksplorować. Smalltalk posiada też wbudowanych wiele ciekawych narzędzi do refaktoryzacji kodu (w tym również stawiał pionierskie kroki). Nawet tak prosta sprawa jak ładne formatowanie kodu jest do załatwienia jednym kliknięciem – piszemy fragment, zaznaczamy go i wybieramy odpowiednią opcję, a Smalltalk poprawi go, dodając białe znaki tu i ówdzie. Sam dokona też chociażby „mądrej” kategoryzacji metod, uwzględniając kategorie metod o tych samych nazwach, znajdujących się w klasach nadrzędnych.
A teraz najlepsze – skoro całe środowisko programistyczne Smalltalka jest napisane w Smalltalku i uruchomione w jego maszynie wirtualnej, to… jest to IDE, które możemy je na żywo dowolnie edytować! Zmieniając odpowiednie wiadomości, możemy całkowicie przebudować IDE według własnego zamysłu. Chcesz dodać nową pozycję w głównym menu? Nie ma problemu! Pragniesz zmodyfikować działanie któregoś z przycisków? Proszę bardzo! Osobiście nie znam żadnego innego tak rozbudowanego, a przy tym tak niesamowicie eleastycznego środowiska programistycznego.
Więcej?
To tylko pierwszy z przygotowywanej przeze mnie serii artykułów o Smalltalku. W kolejnych wpisach poruszę m.in. takie tematy jak:
- Dlaczego warto uczyć się Smalltalka?
- Jakie są jego realne zastosowania?
- Historia Smalltalka i jego dialektów
- Najciekawsze smalltalkowe narzędzia deweloperskie
- Rozwijanie aplikacji webowych w Smalltalku
Jeśli więc temat Cię zainteresował, zachęcam do obserwowania PolyDev.PL!
Linki
- Squeak – oficjalna strona projektu.
- Europejska Grupa Użytkowników Smalltalka (ESUG).
- Blog Richarda K. Enga, popularyzujący Smalltalka.
